Kennst du das? Du startest ein neues Projekt mit einem sauberen Domänenmodell. Deine Order-Entität ist perfekt normalisiert, die Datenbankbeziehungen sind sauber definiert (3. Normalform), und das Speichern einer Bestellung geht blitzschnell. Alles fühlt sich richtig an.
Doch dann kommen die Anforderungen für das Frontend: “Wir brauchen ein Dashboard, das alle Bestellungen anzeigt – gefiltert nach Status, aggregiert nach Produktkategorie, inklusive Kundendaten und Lieferadresse, und bitte mit Volltextsuche.”
Du fängst an, deine schönen Entitäten zu verbiegen. Du schreibst Monster-SQL-Queries mit sieben Joins. Du fügst Indizes hinzu, bis die Festplatte glüht. Trotzdem ächzt die Datenbank unter der Last der Lesezugriffe, und Schreiboperationen werden plötzlich langsam, weil Indizes aktualisiert werden müssen.
Willkommen in der “CRUD-Falle”.
Das Problem ist nicht deine Datenbank. Das Problem ist, dass wir versuchen, ein einziges Modell für zwei völlig gegensätzliche Aufgaben zu nutzen. Die Lösung dafür ist radikal, aber effektiv: CQRS.
Das Problem: Das “God Model” Dilemma
In klassischen CRUD-Anwendungen (Create, Read, Update, Delete) haben wir oft ein einziges Modell (z.B. die JPA Entity Order), das für alles herhalten muss.
- Write (Command): Muss Daten konsistent halten, Regeln validieren (“Ist genug Geld da?”) und normalisiert speichern. Hier zählt ACID (Atomarität, Konsistenz, Isolation, Dauerhaftigkeit).
- Read (Query): Will Daten so schnell wie möglich anzeigen, oft denormalisiert, flach und “Join-frei”. Hier zählt Performance.
Diese Anforderungen widersprechen sich fundamental. Ein Modell, das perfekt zum Schreiben optimiert ist, ist oft furchtbar zum Lesen – und umgekehrt.
Die Lösung: Trennung von Tisch und Bett
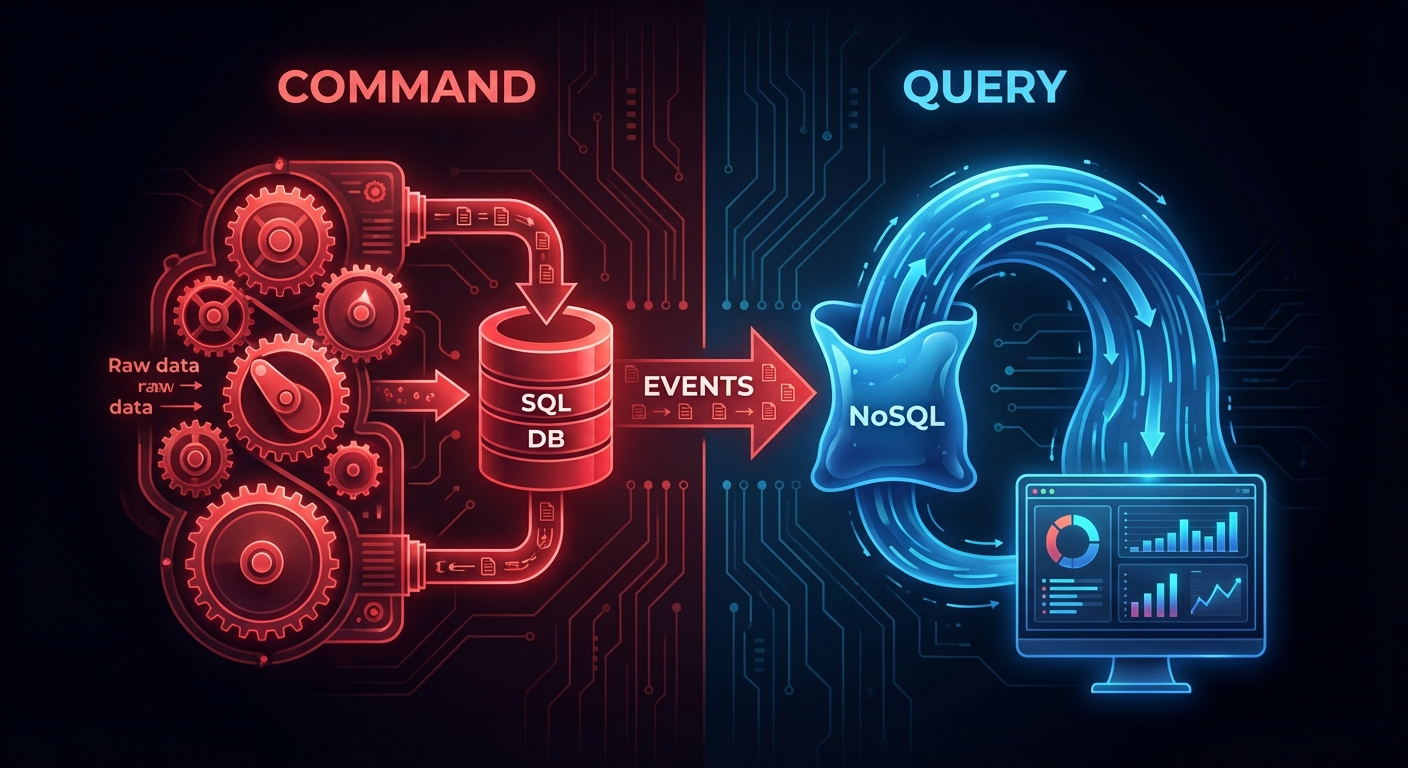
CQRS steht für Command Query Responsibility Segregation. Die Idee ist simpel: Wir teilen unsere Anwendung in zwei logische Hälften.
Die Command Side (Die Schreib-Seite):
- Aufgabe: Daten ändern.
- Input: “Commands” (Imperative Befehle wie
CreateOrderCommand,ShipItemCommand). - Datenbank: Hochgradig normalisiert (z.B. PostgreSQL), optimiert für Transaktionen.
- Return: Nichts (
void) oder nur eine ID. Keine Daten!
Die Query Side (Die Lese-Seite):
- Aufgabe: Daten lesen.
- Input: “Queries” (Fragen wie
GetDashboardDataQuery). - Datenbank: Denormalisiert (z.B. Elasticsearch, MongoDB oder eine flache SQL-Tabelle), optimiert für schnelle Reads (“Read Model”).
- Return: DTOs (Data Transfer Objects), die exakt so aussehen, wie das Frontend sie braucht.
Wie bleiben die Daten synchron?
Jetzt fragst du dich sicher: “Wenn ich zwei Modelle (oder sogar zwei Datenbanken) habe, wie kommen die Daten von A nach B?”
Hier schließt sich der Kreis zu unseren vorherigen Artikeln über Event-Driven Architecture: Events.
Der Ablauf sieht so aus:
- Der Benutzer sendet
CreateOrderCommand. - Der Command Service validiert, speichert in der SQL-DB und feuert ein
OrderCreatedEvent(z.B. via RabbitMQ oder Kafka). - Der Query Service (oder ein “Projector”) hört auf dieses Event.
- Er nimmt die Daten aus dem Event und aktualisiert sein eigenes, optimiertes Lese-Modell (z.B. ein Dokument in Elasticsearch).
Das bedeutet: Unser Lese-Modell hinkt immer ein paar Millisekunden hinterher. Das nennt man Eventual Consistency.
Code-Beispiel: CQRS mit Spring Boot
Schauen wir uns an, wie das im Code aussieht. Wir verabschieden uns vom monströsen OrderService und splitten die Logik.
1. Die Command Side (Schreiben)
Hier passiert die “harte” Arbeit der Geschäftslogik.
@Service
@Transactional
public class CreateOrderHandler {
private final OrderRepository writeRepository; // JPA / Postgres
private final EventPublisher eventPublisher; // Unser Interface zum Message Broker
public void handle(CreateOrderCommand command) {
// 1. Validierung & Logik
if (command.getItems().isEmpty()) {
throw new IllegalArgumentException("Order must have items");
}
// 2. Domain Model erzeugen & speichern (Write Model)
Order order = new Order(command.getCustomerId(), command.getItems());
writeRepository.save(order);
// 3. Event feuern für die Query Side
eventPublisher.publish(new OrderCreatedEvent(order.getId(), order.getItems()));
}
}
2. Der Synchronizer (Der Projector)
Diese Komponente verbindet die beiden Welten. Sie lauscht auf Events und baut das Lese-Modell.
@Component
public class OrderProjector {
private final OrderViewRepository readRepository; // z.B. MongoDB oder Elasticsearch
@EventListener // oder @RabbitListener
public void on(OrderCreatedEvent event) {
// Wir bauen ein optimiertes DTO für die schnelle Anzeige (Read Model)
OrderView view = new OrderView();
view.setOrderId(event.getOrderId());
view.setSummary("Bestellung mit " + event.getItems().size() + " Artikeln");
// Wir berechnen hier schon Dinge vor, damit wir es beim Lesen nicht tun müssen!
view.setSearchTags(generateSearchTags(event));
readRepository.save(view);
}
}
3. Die Query Side (Lesen)
Hier gibt es keine komplexe Logik, keine Joins, nur Geschwindigkeit.
@Service
public class DashboardQueryHandler {
private final OrderViewRepository readRepository;
public List<OrderView> handle(GetDashboardQuery query) {
// Direkter Zugriff auf das vorbereitete Modell.
// Extrem schnell, O(1) oder einfacher Index-Lookup.
return readRepository.findByCustomerId(query.getCustomerId());
}
}
Wann solltest du CQRS nutzen? (Und wann nicht!)
CQRS ist ein mächtiges Werkzeug, aber es erhöht die Komplexität deiner Architektur signifikant (zwei Modelle, Synchronisierung, Eventual Consistency).
Nutze CQRS, wenn:
- Du extremen Traffic hast und Reads/Writes sehr unterschiedlich skalieren müssen (z.B. 1000x mehr Reads als Writes).
- Deine Geschäftslogik beim Schreiben sehr komplex ist, deine Lese-Ansichten aber ganz anders aussehen.
- Du sowieso schon Event Sourcing oder eine Event-Driven Architecture betreibst.
Vermeide CQRS, wenn:
- Du eine einfache CRUD-Anwendung baust.
- “Eventual Consistency” für deinen Anwendungsfall inakzeptabel ist (z.B. der Nutzer muss seine Änderung sofort sehen, ohne Verzögerung).
Fazit
CQRS befreit dein Domänenmodell von der Last der Darstellung. Es erlaubt dir, für das Schreiben Sicherheit (ACID) und für das Lesen Geschwindigkeit (NoSQL/Cache) zu wählen – ohne Kompromisse. Es ist der Schlüssel zu Hochlast-Systemen, aber wie alles in der Software-Architektur: Es ist kein “Free Lunch”. Du zahlst mit Komplexität, gewinnst aber Skalierbarkeit.