Du arbeitest gerade an einem Feature. Claude Code läuft in deinem Terminal, mitten in einem größeren Refactoring. Dann fällt dir ein kritischer Bug in Produktion auf, den du sofort fixen musst. Was jetzt?
Wenn du wie die meisten Entwickler arbeitest: git stash, Branch wechseln, Bug fixen, zurückwechseln, git stash pop, hoffen, dass nichts kollidiert. Und während du das machst, steht dein Agent still – er kann schließlich nicht in einem Repo arbeiten, das du gerade unter ihm wegziehst.
Genau hier zeigt sich ein Problem, das mit klassischer Softwareentwicklung kaum auffällt, mit agentischer Entwicklung aber täglich nervt: Ein Git-Repository hat standardmäßig genau einen Checkout. Ein Branch, ein Working Directory, ein Zustand. Sobald du mehrere Dinge gleichzeitig tun willst – sei es du selbst plus ein Agent, oder mehrere Agents parallel an unterschiedlichen Tasks – wird dieser eine Checkout zum Flaschenhals.
Die Lösung dafür existiert in Git schon seit Version 2.5, wird aber selten genutzt: Git Worktrees. Sie lösen genau das Problem, mit dem parallele Agentic-Workflows sonst kollidieren würden. In diesem Artikel zeige ich dir, wie sie funktionieren und wie du sie konkret einsetzt, um mehrere Coding-Agents gleichzeitig arbeiten zu lassen – ohne dass sie sich gegenseitig in die Quere kommen.
Was sind Git Worktrees?
Ein Git-Repository besteht aus zwei Teilen: dem .git-Verzeichnis mit der kompletten History, allen Branches und Objekten – und dem Working Directory, also den Dateien, die du tatsächlich siehst und bearbeitest. Normalerweise sind das eins zu eins verknüpft: ein .git, ein Working Directory, ein aktiver Branch.
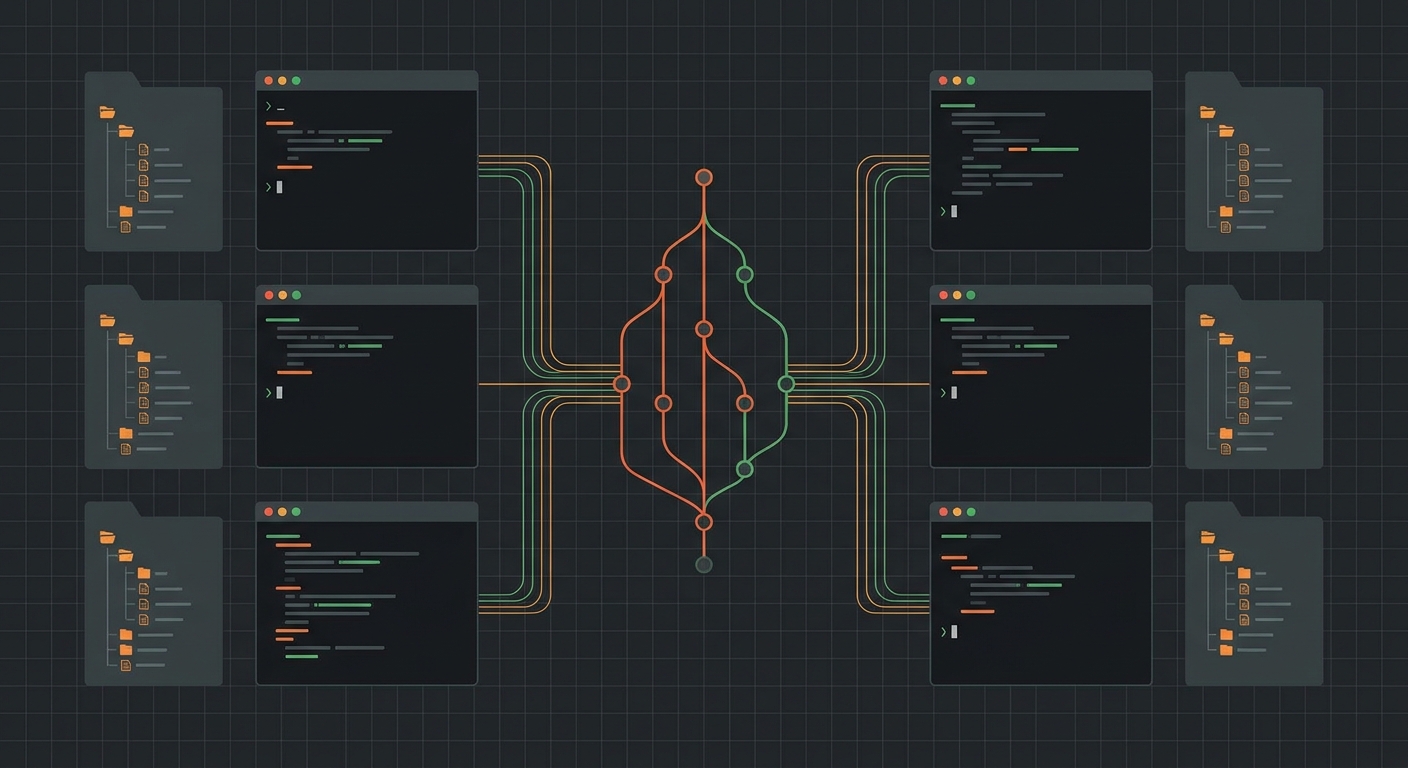
Ein Worktree trennt diese Kopplung auf. Du bekommst mehrere Working Directories, die sich alle dasselbe .git-Verzeichnis teilen. Stell dir das .git-Verzeichnis wie eine zentrale Bibliothek vor, aus der sich mehrere Lesesäle gleichzeitig bedienen – jeder Lesesaal hat sein eigenes Buch aufgeschlagen (seinen eigenen Branch, seinen eigenen Stand), aber alle greifen auf denselben Bestand zu.
Praktisch heißt das: Du kannst main in einem Ordner ausgecheckt haben, während in einem komplett anderen Ordner gleichzeitig feature/payment-refactor läuft – beide gehören zum selben Repository, teilen sich History und Objekte, aber blockieren sich nicht gegenseitig. Kein stash, kein Hin-und-her-Checkout, kein zweites git clone mit doppeltem Speicherbedarf für die komplette History.
Der Befehl dafür ist git worktree. Er verwaltet genau diese zusätzlichen Working Directories – wie viele, wo sie liegen, welcher Branch dort aktiv ist. Wie das im Detail aussieht, kommt gleich im praktischen Teil.
Das Problem (Anti-Pattern)
Stell dir folgendes Setup vor: Du hast Claude Code in deinem Projektordner laufen und lässt es an einem größeren Refactoring arbeiten. Parallel dazu willst du – oder ein zweiter Agent – schnell einen Hotfix bauen. Naheliegend wäre: einfach einen zweiten Terminal-Tab öffnen, im selben Ordner, Branch wechseln, losarbeiten.
Das geht schief, und zwar zuverlässig:
- Checkout-Konflikt:
git checkoutodergit switchwechseln den Branch für das gesamte Working Directory. Wechselst du im zweiten Terminal den Branch, wechselt er auch für den Agent im ersten Terminal – mitten in seiner Arbeit. Seine offenen Datei-Änderungen landen plötzlich auf einem anderen Branch, als er denkt. - Race Conditions bei Datei-Schreibzugriffen: Zwei Prozesse schreiben in dieselben Dateien im selben Verzeichnis. Der Agent liest eine Datei, während du sie im Editor speicherst – wer gewinnt, ist Zufall.
- Uncommitted Changes blockieren dich: Willst du trotzdem wechseln, meldet Git “Your local changes would be overwritten”. Also
stash. Aber wehe, der Agent hat selbst mitten in einemgit addoder Commit gesteckt – dann stasht du seine Arbeit weg, ohne es zu merken. - Build-Artefakte laufen sich gegenseitig über den Haufen: Node-Modules, Compiler-Output, Caches – alles bezieht sich auf einen Dateibaum. Zwei Build-Prozesse auf demselben Baum können sich gegenseitig kaputt schreiben.
Der eigentliche Kern des Problems: Agentic Tools sind darauf ausgelegt, autonom über mehrere Dateien hinweg zu arbeiten – oft minutenlang, ohne dass du jeden Schritt siehst. Genau diese Autonomie macht sie im geteilten Working Directory gefährlich. Ein Mensch merkt meistens sofort, wenn er auf dem falschen Branch tippt. Ein Agent merkt es erst, wenn sein nächster Diff nicht mehr zu dem passt, was er im Kontext hat.
Die Lösung (Best Practice)
Statt mehrerer Prozesse in einem Working Directory bekommt jeder Agent – und du selbst – ein eigenes. Alle greifen auf dasselbe .git-Verzeichnis zu, arbeiten aber komplett isoliert voneinander. So richtest du das ein:
Einen neuen Worktree für einen existierenden Branch anlegen:
# Im Hauptverzeichnis deines Repos
git worktree add ../mein-projekt-hotfix hotfix/payment-bug
Das legt einen neuen Ordner ../mein-projekt-hotfix an, checkt dort den Branch hotfix/payment-bug aus – und lässt deinen ursprünglichen Checkout dabei komplett unberührt.
Einen neuen Worktree mit neuem Branch in einem Schritt:
git worktree add -b feature/rate-limiting ../mein-projekt-rate-limiting
Das erstellt gleichzeitig den Branch feature/rate-limiting und den passenden Worktree dafür. Praktisch, wenn du für jeden Agent-Task direkt einen frischen Branch willst.
Alle aktiven Worktrees anzeigen:
git worktree list
/Users/julian/projekte/mein-projekt abcd123 [main]
/Users/julian/projekte/mein-projekt-hotfix ef01234 [hotfix/payment-bug]
/Users/julian/projekte/mein-projekt-rate-limiting 567890a [feature/rate-limiting]
Einen Worktree wieder entfernen, wenn die Arbeit erledigt ist:
git worktree remove ../mein-projekt-hotfix
Wichtig: git worktree remove löscht den Ordner nur, wenn es keine uncommitted Changes gibt. Hast du dort noch offene Änderungen, verweigert Git das Entfernen – ein sinnvoller Schutz, damit du nicht versehentlich Agent-Arbeit wegwirfst, die noch nicht gesichert ist.
Aufräumen, wenn ein Ordner von Hand gelöscht wurde:
Falls du einen Worktree-Ordner mal manuell im Finder oder mit rm -rf entfernt hast, statt über Git, bleibt intern noch ein Verweis darauf bestehen. Das räumst du so auf:
git worktree prune
Damit hast du das Werkzeug an der Hand. Der eigentliche Nutzen zeigt sich aber erst im konkreten Agentic-Workflow – dazu jetzt mehr.
Praktischer Workflow
Jetzt wird’s konkret: Du hast drei Dinge zu tun. Ein größeres Feature soll voranschreiten, ein Bug in Produktion muss weg, und ein drittes Thema brauchst du für Review. Statt das sequenziell abzuarbeiten, teilst du die Arbeit auf mehrere Worktrees auf – und lässt in jedem einen eigenen Claude Code laufen.
Schritt 1: Worktrees für jeden Task anlegen
cd ~/projekte/mein-projekt
git worktree add -b feature/rate-limiting ../mein-projekt-rate-limiting
git worktree add -b hotfix/payment-bug ../mein-projekt-hotfix
git worktree add -b review/pr-142 ../mein-projekt-review origin/feature/pr-142
Der dritte Befehl checkt gleich einen bestehenden Remote-Branch aus – praktisch, wenn du einen Pull Request lokal reviewen willst, ohne deinen eigenen Checkout dafür zu opfern.
Schritt 2: In jedem Worktree einen eigenen Agent starten
# Terminal-Tab 1
cd ~/projekte/mein-projekt-rate-limiting
claude
# Terminal-Tab 2
cd ~/projekte/mein-projekt-hotfix
claude
# Terminal-Tab 3
cd ~/projekte/mein-projekt-review
claude
Jede Instanz von Claude Code arbeitet jetzt in ihrem eigenen Verzeichnis, auf ihrem eigenen Branch, komplett unabhängig von den anderen. Der Agent im Hotfix-Worktree kann committen, während der Agent im Feature-Worktree mitten in einem Refactoring steckt – keiner stört den anderen, weil keiner die Dateien des anderen sieht.
Schritt 3: Fertige Arbeit zusammenführen
Sobald ein Task fertig ist, läuft der Merge wie gewohnt über den Hauptcheckout:
cd ~/projekte/mein-projekt
git checkout main
git merge hotfix/payment-bug
git push
Schritt 4: Worktree aufräumen, wenn er nicht mehr gebraucht wird
git worktree remove ../mein-projekt-hotfix
git branch -d hotfix/payment-bug
Das Ergebnis: Du kannst so viele parallele Agent-Sessions laufen lassen, wie deine Maschine verträgt – jede isoliert, jede auf ihrem eigenen Branch, ohne dass du zwischen Tasks manuell stashen oder Kontext wechseln musst. Der Flaschenhals aus der Einleitung ist damit aufgelöst.
Pro-Tipps / Warnungen
Node-Modules & Dependencies pro Worktree Jeder Worktree hat sein eigenes Working Directory – aber keine eigenen
node_modules,vendor-Ordner oder virtuellen Environments. Die musst du in jedem Worktree separat installieren:cd ../mein-projekt-rate-limiting npm installKostet zusätzlichen Speicherplatz und Zeit beim Setup. Bei sehr großen Dependency-Bäumen lohnt sich ein Blick auf Package-Manager mit globalem Cache (z.B. pnpm), die installierte Pakete zwischen Worktrees teilen statt sie zu duplizieren.
.env-Dateien werden nicht automatisch mitkopiert
.env-Dateien liegen typischerweise in.gitignoreund landen deshalb nicht in einem neuen Worktree. Du musst sie manuell kopieren oder verlinken:cp ~/projekte/mein-projekt/.env ../mein-projekt-rate-limiting/.envVergisst du das, startet dein Agent mit fehlender Konfiguration – und meldet im schlechtesten Fall erst nach einigen Minuten Arbeit einen Verbindungsfehler zur Datenbank.
Speicherplatz im Blick behalten Das
.git-Verzeichnis wird geteilt, aber jedes Working Directory belegt seinen eigenen Platz für Quellcode, Dependencies und Build-Output. Drei bis vier parallele Worktrees mit vollennode_modulessummieren sich schnell auf mehrere Gigabyte. Räume Worktrees zeitnah auf, sobald ein Task erledigt ist – nicht erst, wenn die Festplatte voll ist.
Cleanup nicht vergessen Ein Worktree, den du nicht mehr brauchst, aber nicht entfernst, bleibt in
git worktree listsichtbar und verwirrt beim nächsten Mal, wenn du dich fragst, welcher Branch wo liegt. Baue dir eine Routine: Nach jedem Merge direktgit worktree removeundgit branch -d.
IDE-Konfiguration pro Worktree Öffnest du jeden Worktree als eigenes Projekt in deiner IDE, bekommst du auch pro Worktree eigene Einstellungen, Run-Configurations und offene Tabs – nützlich, wenn du zwischen den Tasks wirklich saubere Trennung willst. Der Nachteil: Einstellungen wie Code-Style oder Debugger-Configs, die nicht versioniert sind, musst du in jedem Worktree einmal einrichten.
Fazit
Git Worktrees lösen ein Problem, das mit klassischer Einzelarbeit kaum auffällt, mit agentischer Entwicklung aber täglich Zeit kostet: der eine Checkout, der zum Flaschenhals wird, sobald mehr als ein Prozess gleichzeitig am Repository arbeiten will. Ein .git-Verzeichnis, mehrere unabhängige Working Directories – jeder Agent bekommt seinen eigenen Branch, seine eigenen Dateien, ohne dass sich irgendwer in die Quere kommt.
Der Umstieg kostet dich ein paar Minuten Setup: Dependencies pro Worktree installieren, .env-Dateien kopieren, eine Cleanup-Routine etablieren. Dafür bekommst du echte Parallelität – mehrere Claude Code Instanzen, die gleichzeitig an unterschiedlichen Tasks arbeiten, ohne dass du zwischen ihnen manuell stashen oder umschalten musst.
Je mehr Verantwortung du an Agents abgibst, desto wichtiger wird sauberes Tooling um sie herum. Worktrees sind dafür ein kleiner, aber wirkungsvoller Baustein.