Einleitung – Das Dilemma verteilter Transaktionen
Stell dir vor, du entwickelst eine klassische E-Commerce-Anwendung. Ein Kunde klickt auf “Kaufen”, und im Hintergrund wird ein Prozess angestoßen, der aus mehreren Schritten besteht:
- Die Bestellung wird in der Datenbank angelegt.
- Die Zahlung über einen Payment-Anbieter wird autorisiert.
- Der Lagerbestand des gekauften Produkts wird reduziert.
In einer monolithischen Architektur, in der alle Module auf eine einzige Datenbank zugreifen, ist das eine alltägliche Aufgabe. Wir packen diese drei Operationen in eine einzige Datenbanktransaktion. Mit einer einfachen @Transactional-Annotation stellen wir sicher, dass das ACID-Prinzip (Atomarität, Konsistenz, Isolation, Dauerhaftigkeit) gewahrt bleibt. Entweder alle drei Schritte sind erfolgreich, oder keiner davon wird permanent gespeichert. Schlägt die Zahlung fehl, wird auch die Bestellanlage und die Inventar-Reduzierung zurückgerollt. Alles oder nichts. Einfach, sicher, bewährt.
Doch was passiert, wenn unsere Anwendung wächst und wir uns für eine moderne Microservice-Architektur entscheiden? Plötzlich haben wir statt eines einzigen Systems mehrere spezialisierte Dienste: einen Order Service, einen Payment Service und einen Inventory Service. Jeder dieser Dienste hat seine eigene, unabhängige Datenbank.
Die logische Geschäftsoperation “Bestellung aufgeben” erstreckt sich nun über drei verschiedene Systeme. Eine datenbankübergreifende 2-Phasen-Commit (2PC) wäre theoretisch eine Lösung, ist aber in der Praxis oft zu komplex, langsam und schlecht skalierbar. Die gemütliche Sicherheit einer einzigen Transaktion ist dahin.
Hier stehen wir vor dem zentralen Problem: Wie gewährleisten wir die Konsistenz unserer Daten über Service-Grenzen hinweg? Was passiert, wenn der Payment Service einen Fehler meldet, nachdem der Inventory Service den Lagerbestand bereits erfolgreich reduziert hat? Wir hätten ein Produkt weniger im Lager, aber keinen passenden Zahlungseingang – ein inkonsistenter und geschäftsschädigender Zustand.
Genau für dieses Dilemma wurde das SAGA Pattern entwickelt.
Freut mich, dass die Einleitung passt. Dann knüpfen wir jetzt direkt daran an und erklären das Herzstück des Ganzen.
Hier ist der Entwurf für den zweiten Abschnitt, in dem wir das SAGA Pattern konzeptionell vorstellen.
Was ist das SAGA Pattern? Eine konzeptionelle Einführung
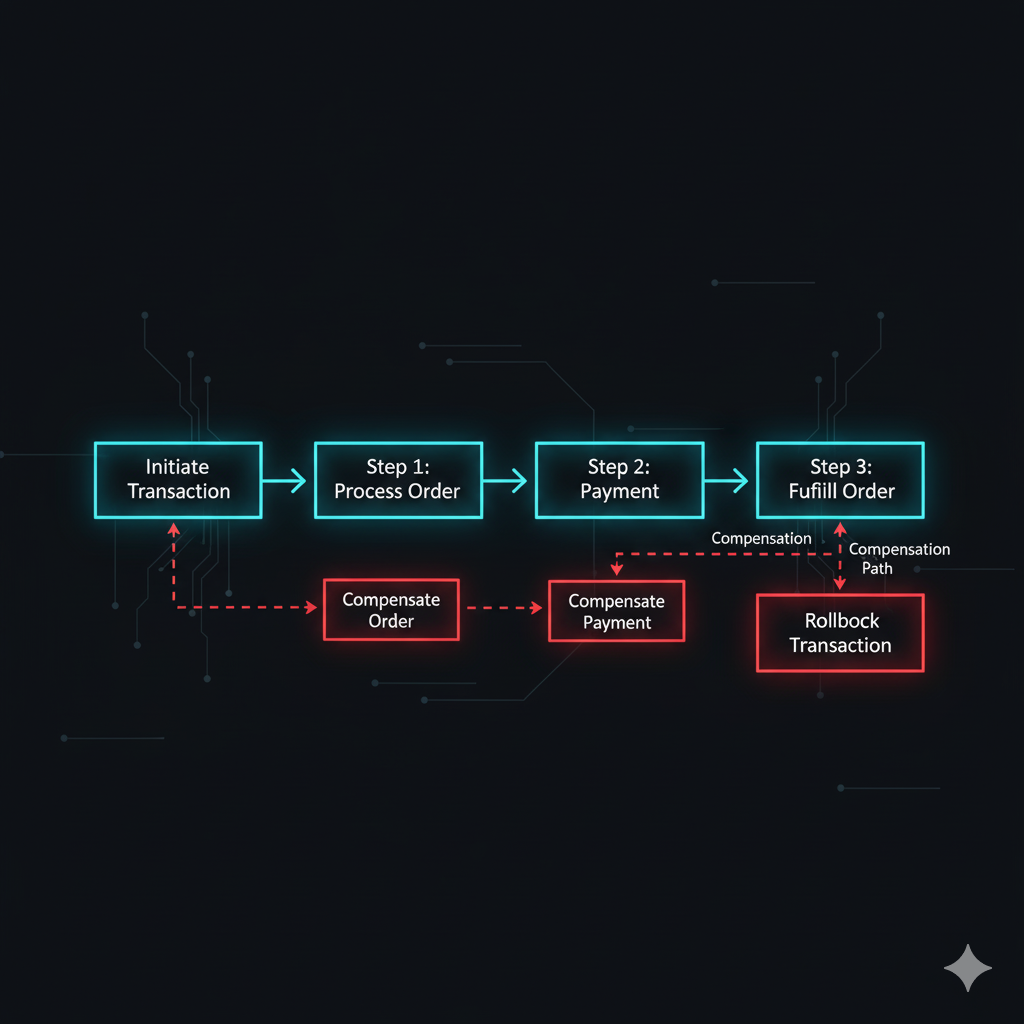
Das SAGA Pattern löst das Problem der verteilten Transaktionen, indem es eine lange, übergreifende Geschäftslogik in eine Sequenz von einzelnen, lokalen Transaktionen aufteilt. Jeder Microservice ist nur für seine eigene, atomare Transaktion verantwortlich. Wenn eine lokale Transaktion erfolgreich ist, stößt sie den nächsten Schritt in der Kette an.
Um bei unserem E-Commerce-Beispiel zu bleiben, würde die “Bestellung aufgeben”-Saga wie folgt aussehen:
- Schritt 1: Der
Order Servicelegt die Bestellung mit dem StatusPENDINGan (Lokale Transaktion A). - Schritt 2: Der
Payment Serviceversucht, die Zahlung des Kunden zu verarbeiten (Lokale Transaktion B). - Schritt 3: Der
Inventory Servicereduziert den Lagerbestand für das bestellte Produkt (Lokale Transaktion C).
Der entscheidende Punkt ist: Jeder dieser Schritte ist für sich genommen konsistent. Der Inventory Service weiß nichts über Zahlungen, und der Order Service kümmert sich nicht um den Lagerbestand. Das System als Ganzes erreicht am Ende einen konsistenten Zustand, was man als “Eventual Consistency” bezeichnet.
Das Konzept ist übrigens keine brandneue Erfindung der Microservice-Ära. Es wurde bereits 1987 in einem Paper von Hector Garcia-Molina und Kenneth Salem beschrieben, um die Konsistenz in “Long Lived Transactions” (LLTs) zu gewährleisten.
Zur Umsetzung einer Saga gibt es zwei etablierte Ansätze:
1. Choreography (Choreografie)
Stell dir eine Gruppe von Tänzern vor, die ohne einen zentralen Dirigenten agieren. Jeder Tänzer kennt seine Rolle und reagiert auf die Aktionen der anderen. Bei der Choreografie-basierten Saga funktioniert das genauso über Events:
- Der
Order Servicelegt eine Bestellung an und publiziert einOrderCreated-Event. - Der
Payment Servicehört auf dieses Event, verarbeitet die Zahlung und publiziert einPaymentSuccessful-Event. - Der
Inventory Servicereagiert darauf und aktualisiert den Lagerbestand.
Dieser Ansatz ist dezentral und flexibel. Bei wenigen Teilnehmern ist er einfach umzusetzen. Bei komplexen Abläufen kann es jedoch schnell unübersichtlich werden, den gesamten Prozessfluss nachzuvollziehen.
2. Orchestration (Orchestrierung)
Hier gibt es, wie im Orchester, einen zentralen Dirigenten – den Orchestrator. Dieser ist eine eigene Komponente oder ein Prozess, der den gesamten Ablauf der Saga steuert.
- Der Orchestrator empfängt die ursprüngliche Anfrage (z.B. “Bestellung aufgeben”).
- Er ruft den
Order Serviceauf, um die Bestellung anzulegen. - Nach erfolgreicher Rückmeldung ruft er den
Payment Serviceauf. - Anschließend kontaktiert er den
Inventory Service.
Der Orchestrator kennt den gesamten Ablauf, verwaltet den Zustand der Saga und entscheidet, welcher Schritt als Nächstes ausgeführt wird. Das macht den Prozess explizit und einfacher zu überwachen, führt aber auch eine zentrale Komponente ein, die zum Flaschenhals werden könnte.

Die Schlüsselkomponente: Kompensierende Transaktionen
Das Besondere und gleichzeitig Herausfordernde am SAGA Pattern ist der Umgang mit Fehlern. Da wir keine übergreifende, atomare Transaktion haben, können wir im Fehlerfall nicht einfach alles zurückrollen, als wäre nichts geschehen. Stattdessen müssen wir die bereits erfolgreich abgeschlossenen lokalen Transaktionen aktiv rückgängig machen. Genau hierfür sind kompensierende Transaktionen da.
Eine kompensierende Transaktion ist, wie der Name schon sagt, eine Aktion, die die Auswirkungen einer zuvor ausgeführten lokalen Transaktion neutralisiert oder rückgängig macht. Sie stellt sicher, dass das System auch bei einem Fehler in einem der Saga-Schritte wieder in einen konsistenten Zustand gelangt.
Kehren wir zu unserem E-Commerce-Beispiel zurück:
Der
Order Servicelegt die Bestellung mit dem StatusPENDINGan. (Lokale Transaktion A erfolgreich)Der
Payment Serviceversucht, die Zahlung zu verarbeiten.- Szenario 1: Zahlung erfolgreich. Die Saga läuft weiter.
- Szenario 2: Zahlung schlägt fehl! Jetzt haben wir ein Problem. Der
Order Servicehat bereits eine Bestellung angelegt, aber keine Zahlung ist eingegangen. Hier muss die Saga rückgängig gemacht werden.
In diesem Fehlerfall würde die kompensierende Transaktion ausgelöst:
- Der
Order Servicemuss die zuvor angelegte Bestellung stornieren oder auf den StatusCANCELLEDsetzen. (Kompensierende Transaktion für Lokale Transaktion A)
Ein weiteres Beispiel, wenn die Saga weiterläuft:
Der
Order Servicelegt die Bestellung an.Der
Payment Serviceverarbeitet die Zahlung erfolgreich.Der
Inventory Serviceversucht, den Lagerbestand zu reduzieren.- Szenario 3: Inventarreduzierung schlägt fehl! Vielleicht ist das Produkt gerade vergriffen oder ein technischer Fehler tritt auf. Nun haben wir eine Bestellung und eine erfolgreiche Zahlung, aber keinen reduzierten Lagerbestand. Das ist immer noch ein inkonsistenter Zustand.
Auch hier kommen kompensierende Transaktionen ins Spiel:
- Der
Payment Servicemuss die zuvor getätigte Zahlung stornieren oder rückbuchen. (Kompensierende Transaktion für Lokale Transaktion B) - Der
Order Servicemuss die Bestellung stornieren oder auf den StatusCANCELLEDsetzen. (Kompensierende Transaktion für Lokale Transaktion A)
Es ist entscheidend, dass jede lokale Transaktion in einer Saga eine zugehörige kompensierende Transaktion haben sollte, die ihre Auswirkungen neutralisieren kann. Diese kompensierenden Aktionen sind selbst lokale Transaktionen und müssen atomar und idempotent sein, d.h., sie können mehrfach aufgerufen werden, ohne unerwünschte Nebeneffekte zu erzeugen.
Die Herausforderung liegt darin, die Kette der Kompensationen korrekt zu orchestrieren und sicherzustellen, dass sie auch im Fehlerfall zuverlässig ausgeführt werden. Dies ist oft komplexer als die eigentliche Vorwärtsbewegung der Saga.
Sehr gut. Dann sind wir bereit für den Abschluss des ersten Teils. Wir fassen die Kernpunkte zusammen und machen dem Leser Appetit auf die Fortsetzung, in der wir dann in den Code eintauchen.
Fazit und Ausblick auf Teil 2
Das SAGA Pattern ist eine mächtige, aber auch anspruchsvolle Antwort auf eine der größten Herausforderungen in Microservice-Architekturen: die Wahrung der Datenkonsistenz über Service-Grenzen hinweg. Statt auf komplexe und oft unpraktikable verteilte Transaktionen wie 2-Phasen-Commits zu setzen, zerlegt eine Saga einen Geschäftsprozess in eine Kette von lokalen Transaktionen.
Die wichtigsten Erkenntnisse aus diesem ersten Teil sind:
- Problem: Klassische ACID-Transaktionen funktionieren nicht über mehrere, unabhängige Datenbanken in einer Microservice-Landschaft.
- Lösung: Das SAGA Pattern koordiniert eine Sequenz von lokalen Transaktionen, um einen Geschäftsprozess abzuschließen.
- Fehlerbehandlung: Scheitert ein Schritt in der Saga, werden kompensierende Transaktionen ausgeführt, um die Aktionen der vorherigen, erfolgreichen Schritte rückgängig zu machen.
- Konsistenz: Eine Saga führt das System in einen Zustand der “Eventual Consistency”. Das bedeutet, dass die Daten nicht zu jedem Zeitpunkt, aber letztendlich konsistent sind.
Mit diesem grundlegenden Verständnis haben wir die Basis geschaffen. Doch die Theorie ist nur die halbe Miete. Die wirklich spannenden Fragen sind: Wie implementiert man eine Saga in der Praxis? Wie geht man mit Concurrency-Problemen um? Und wie stellt man sicher, dass die Kompensationen auch wirklich zuverlässig ausgeführt werden?
Genau diesen Fragen widmen wir uns im zweiten Teil dieser Serie. Dort werden wir eine konkrete Saga – entweder per Choreografie oder Orchestrierung – mit Spring Boot und RabbitMQ (oder Kafka) implementieren und die Konzepte, die wir hier besprochen haben, mit Leben füllen. Bleib dran!